B端业务的数据特点
那么产业互联网背景下toB端业务的数据平台,与toC业务有什么不同呢?B端业务的大数据是怎么玩的,它有什么特点,有什么新奇玩法呢?
说到特点,我想起14年iphone6发布时的广告文案:“比大更大”!
有同学说了,你就吹吧,还能比BAT还大?我说是,也不是,它有自己的大法
这是大数据的4V特征,我们就从这4个维度上,看下产业互联网大数据是怎么个大法:
巨量(Volume):B端业务带来更大的实体数量、更大的深度。我们知道1笔电商订单可能包含n个货物,每个货物可能有n个提货地址,然后会由多个物流员完成多个节点的服务,包括提货、集货、干线、分拨、再干线、再分拨、配送、回单等等。而这个过程的每1段,系统都会产生单独的调度指令,然后根据具体的服务,产生多笔不同主体、不同科目的记账指令。
高速(Velocity):互联网平台的价值,toC端在于给到消费者更好的体验;而toB时,则在于给予B端客户更高的效率。以物流为例,平台的价值,在于让客户的 人货车场物钱更高速的协同,在单位时间内完成生产更多的服务。而提速的手段就是更快的数据分发、更智能的数据计算
多样(Variety):在B端业务里,有“5流”的说法,即:商流、物流、资金流、信息流、服务流;它们涵盖了从商业到生产的全部层次。而当5流全部线上化以后,就产生了更多样的数据,比如客户关系、市场和销售的活动记录、产品的型号、路径、成本、生产计划和服务的SOP、财务的应收应付、实收实付以及逾期管理等等。
价值(Value):正是因为B端业务“更深”的延伸到每个客户的“5流”数据,因此,利用这些数据可以产生客户更完整、更真实的画像,也产生更大的价值。随便举个例子,这种形式下“刷单”几乎是不可能的,因为刷了订单,运单是核对不过的,再刷了运单,结果车单又不对了,然后是账务记录、成员积分、车辆定位等等。这些数据都是彼此关联的整体,它对业务活动的记录更加完整。
“一个例子”——货物联运的时效监控与调度系统
在卡行,我们利用数据的快速分析和传递,来帮助接入的每个物流公司的提升运作效率。尽可能利用数据能力,使我们的网络成员能够更好地为客户服务。
2017年底,数据团队为枢纽伙伴构建了一套物流时效的全链路监控系统,帮助提升成员的自动调度能力
系统目标
- 提高全链路的运输时效,降低人工成本。
- 改变被动服务变成主动服务,提高客户满意度。
主要功能
精确跟踪每一票货物,在每一个环节上的时效状态,实现实时反馈和智能预警。

这是运输路径的示意图,货物发出以后,由提货成员运到附近的枢纽,在经过枢纽的集货和转运,交给干线成员完成省到省、市到市到长途干线运输;然后交给目的地的枢纽,目的地枢纽会完成本地共享配送,最终将货物安全的交给收货客户。
从图上可以看到整个过程,经过的环节非常多,要让这些环节的配合达到最优。需要大量的数据实时的传递,这给数据平台带来前所未有的挑战。
主要挑战:
- 复杂性 ,来自产品_成员_订单/运输等多个板块的复杂数据关系;
- 实时性,低延迟、高可用的数据管道;
- 精确性,看板上的每个数字必须精确;
- 拓展性,为成百上千家枢纽提供多个垂直数据看板,并支持拓展至成千上万。
数据平台架构
如何满足这些要求呢?首先看下系统的整体架构。
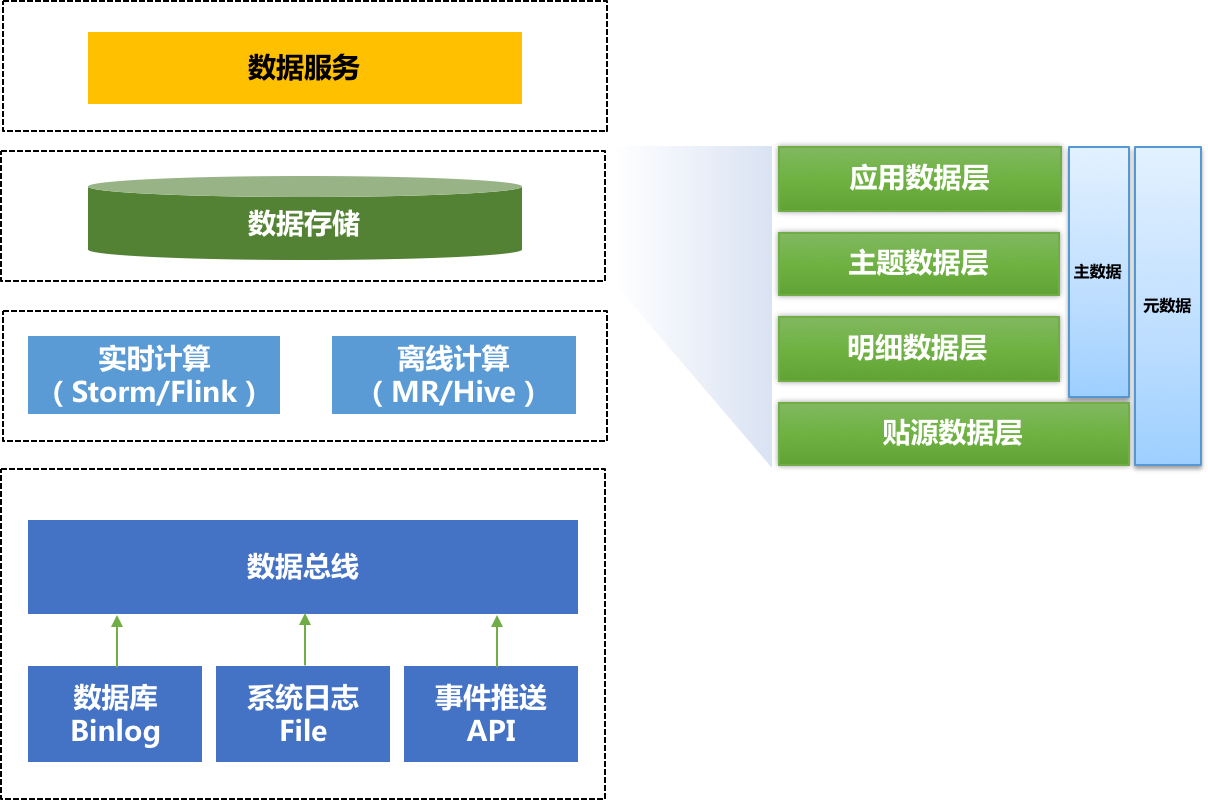
- 数据采集层,位于架构的最低层,我们通过数据总线技术汇总来自关系数据库、日志文件、用户行为和物联网的消息和事件,然后转换为统一Schame的数据流;
- 计算层, 提供了实时和批量的两个模式的计算能力,来实现实时性和准确性间的最大平衡;
- 存储层, 我们会根据数据的处理过程,划分不同的横向数据层次;同时根据我们的业务建模,划分不同的纵向领域;
- 数据服务层,位于架构的最顶层,为不同用户场景,提供不能的查询能力。比如存量数据的多维度聚合、实时数据的推送、全量明细的检索等等;
关键设计与技术
下面的章节,为读者逐一介绍架构各层的设计思路与关键技术。
数据模型
仔细分析上面的示例就会发现,由于业务链条长,中间环节多,参与元素繁杂,造成数据需求的复杂化和多样化。为了提升对数据用户的交付效率,同时,实现数据资产的有效积淀。基于对自身业务的高度抽象,我们参考领域驱动设计的基础上,对数据模型进行了深度的分析和设计。
下面是数据模型的整体架构:
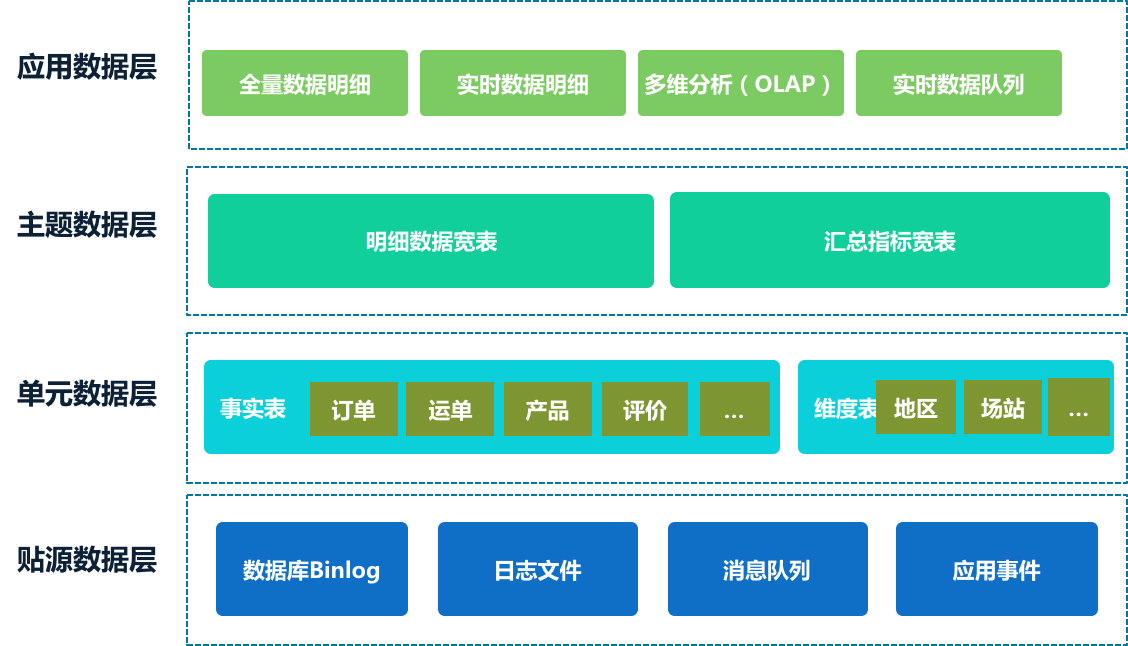
模型构成:
- 应用数据层:具体需求而构建的应用层
- 主题数据层:补充维度后的数据,采用宽表模型,并汇总标准指标。
- 单元数据层:整合领域事实数据的全量明细
- 贴源数据层:原始数据实时队列。
基于多层模型的递进式数据转换设计,基于对物流平台业务的深入理解,设计出抽象、内聚、职责单一的数据模型,并不断演进。
有效避免了Case by Case的重复建设,有效提升数据产品交付效率。同时,也支持在不断层面做数据存储和计算的针对性优化 。
实时数据总线
由于业务场景非常丰富,新数据源的接入成为常态。比如,货架上RFID的应用,用来跟踪和收集货物的仓位数据。类似这种新数据的接入,如果每次都修改数据分析的代码,在交付效率上是无法接受的。
为实现不同数据源的快速对接,尤其是新数据源的对接。同时为下游数据分析、计算提供标准的数据与接口,避免数据源的复杂性向下游传导,我们设计了统一的实时数据总线。总线实现了跨数据源的标准数据封装格式,通过元数据配置,实现数据格式的转换,以及下游的数据订阅。
数据总线的处理流程如下:
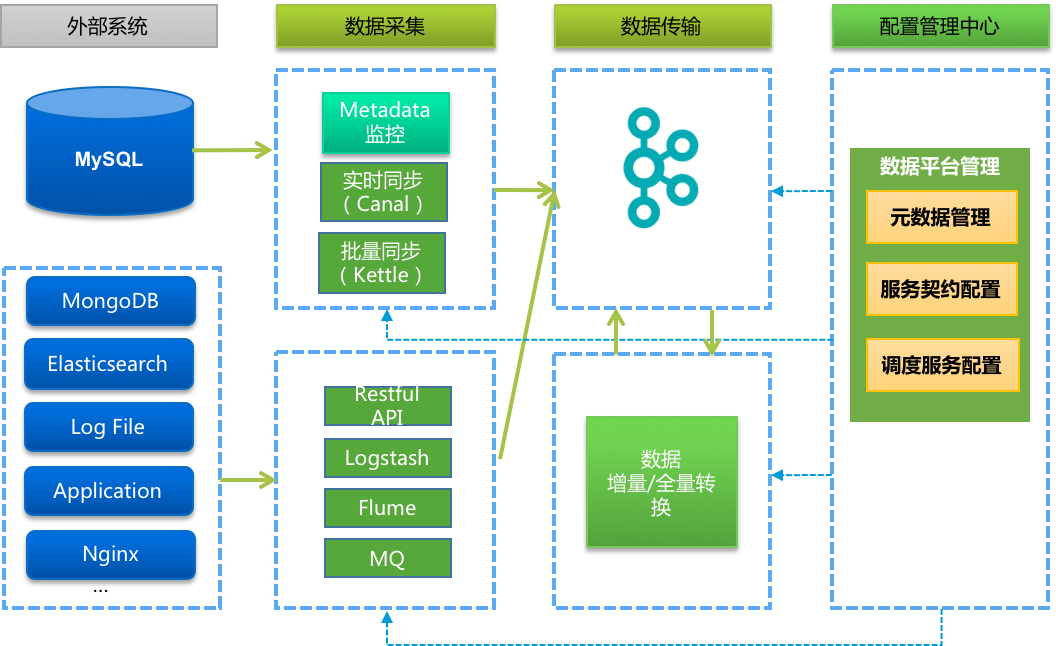
总体的设计思路如下:
- 数据采集,负责对接不同的数据源,实现实时抽取出增量数据,并支持批量抽取。其中对MySQL数据库会采用Binlog订阅方式抽取;对于事件、日志类型支持多种Agent对接;
- Metadata监控模块,监听数据源的Schema变化,并实现记录、报警;
- 所有数据事件,被转换为统一格式发布在Kafka的Topic上;
- 数据总线,接入数据平台统一的配置管理中心。实现元数据、数据源契约和调度的管理
- 为了价值最大化,数据总线不单服务于数据平台本事,还服务于数据平台与业务系统、业务系统与业务系统间的数据交换。
流计算引擎
示例系统要求数据的实时性和精确性,既要满足数据从发生到目标用户的最低延迟,同时要求对原始数据进行准确关联和规则判断。这对数据平台的流计算引擎提出了更高的要求。
B端业务对流计算的要求,总结如下:
- 较低的延迟;
- 支持有状态的计算,并支持故障时的状态恢复;
- 对高级语义的良好支持;
- 以优雅的方式处理峰值流量;
- 敏捷的编程模型,以应对频繁变更的需求;
- 可拓展的性能;
- …
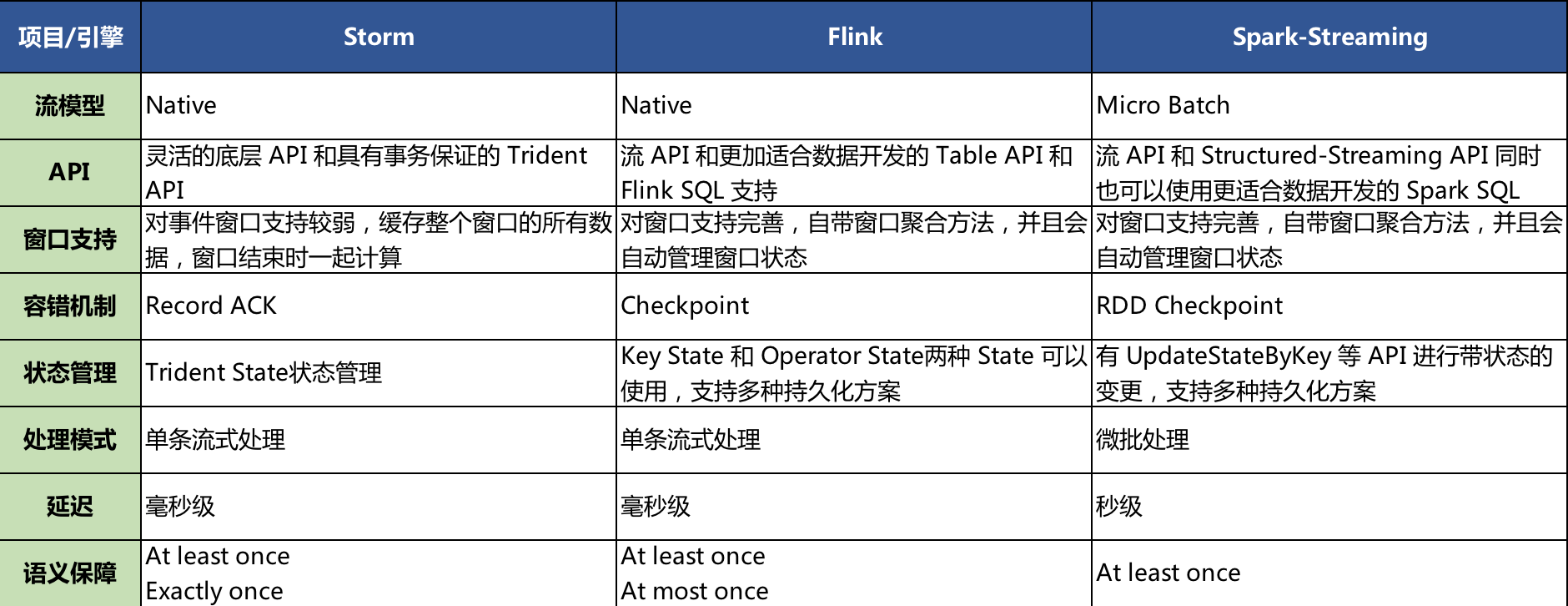
经过对主流Framework的深入分析,我们最后选择了Flink作为流计算引擎的底层框架。并在Flink基础上,构建了流计算的工程体系:
- 数据工程师,面向Flink基础设施的开发和维护。比如:通用Operator的开发、State Backend的配置、不同场景的性能调优等;
- 数据分析师,以及,面向业务客户的沟通和数据模型的设计与升级,通过大量实践,不断优化上文所述的各层模型。
- ETL工程师,根据业务需求,编写基于Flink SQL的数据转换代码。并通过数据平台的Web Console完成测试和发布。
下面我们用几个简单的例子,演示一下基于Flink的ETL开发模式。
- 数据流Join
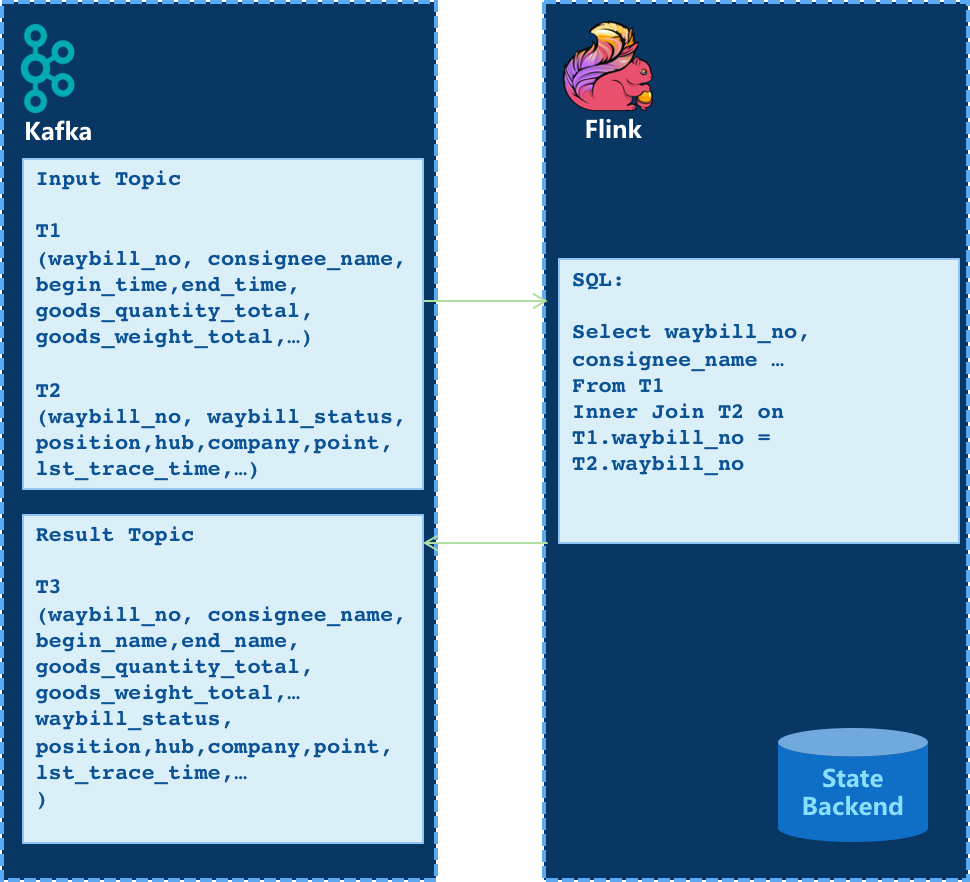
- 简单时效判断
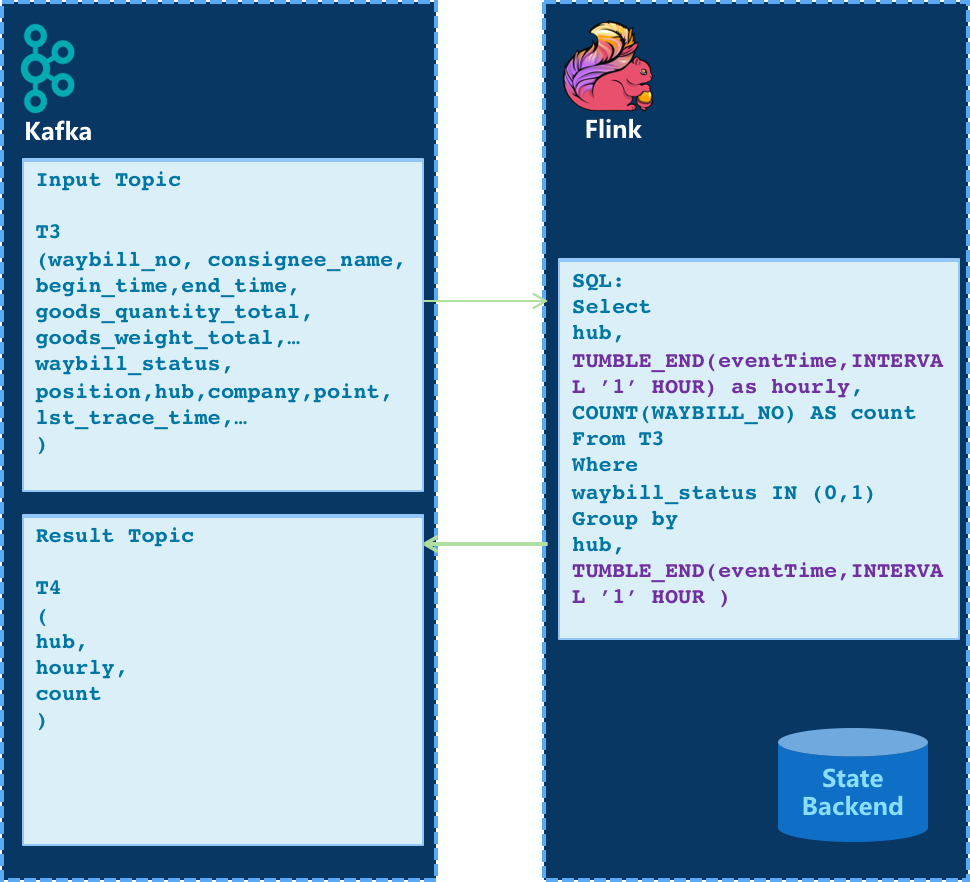
- Flink CEP规则
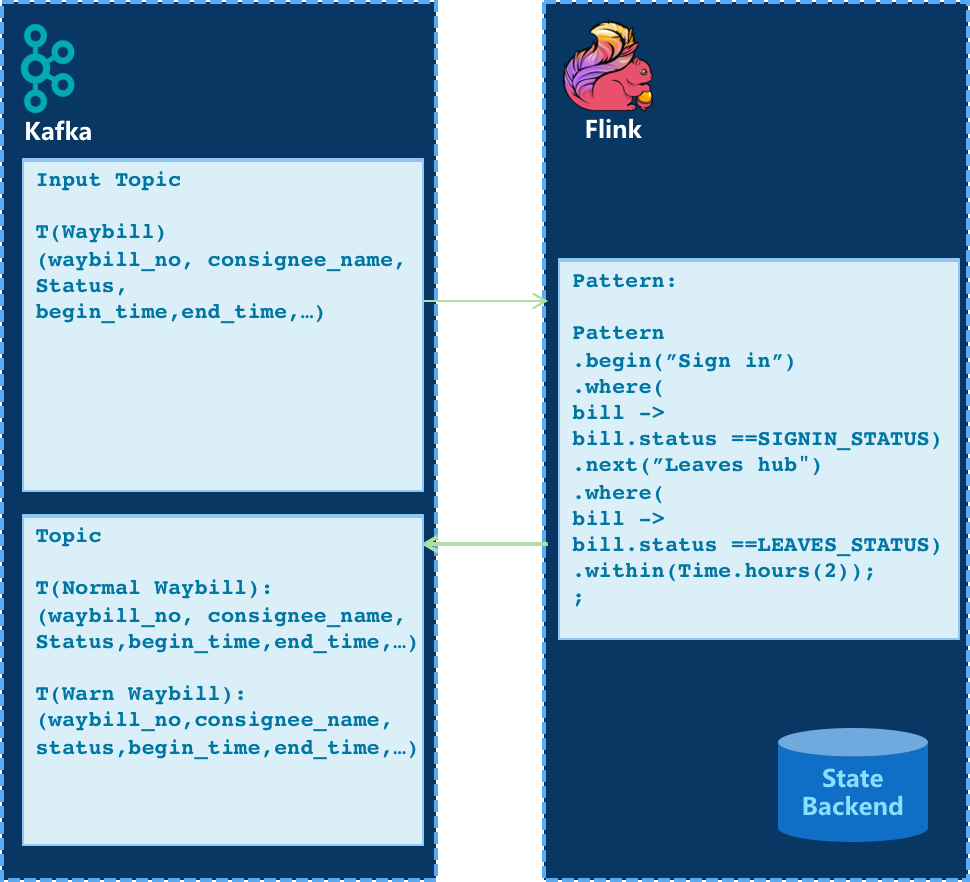
关于Flink的一些Tips:
- 参照业务活动划分事件流,以控制状态存储的膨胀;
- 将业务逻辑模块化,并注册为Flink UDF,提高业务交付效率;
- 使⽤Asyn I/O 调⽤外部业务系统接⼝ ;
- 充分利用RocksDB的性能优势,优化State backend;
复杂事件处理机制
虽然Flink CEP 解决了部分场景的规则判断问题,但是面对较复杂的场景仍然稍显不足。
比如:
首家枢纽车辆签到时间在路由产品的截单时间-1小时前的,路由的最末端站点或枢纽,需在规定路由时效内23:59:59前完成系统签收;否则时效+1天;
因此,除Flink CEP外,我们还引入了专门的规则引擎服务,实现流计算节点内的复杂规则匹配问题。
整体框架示意图:
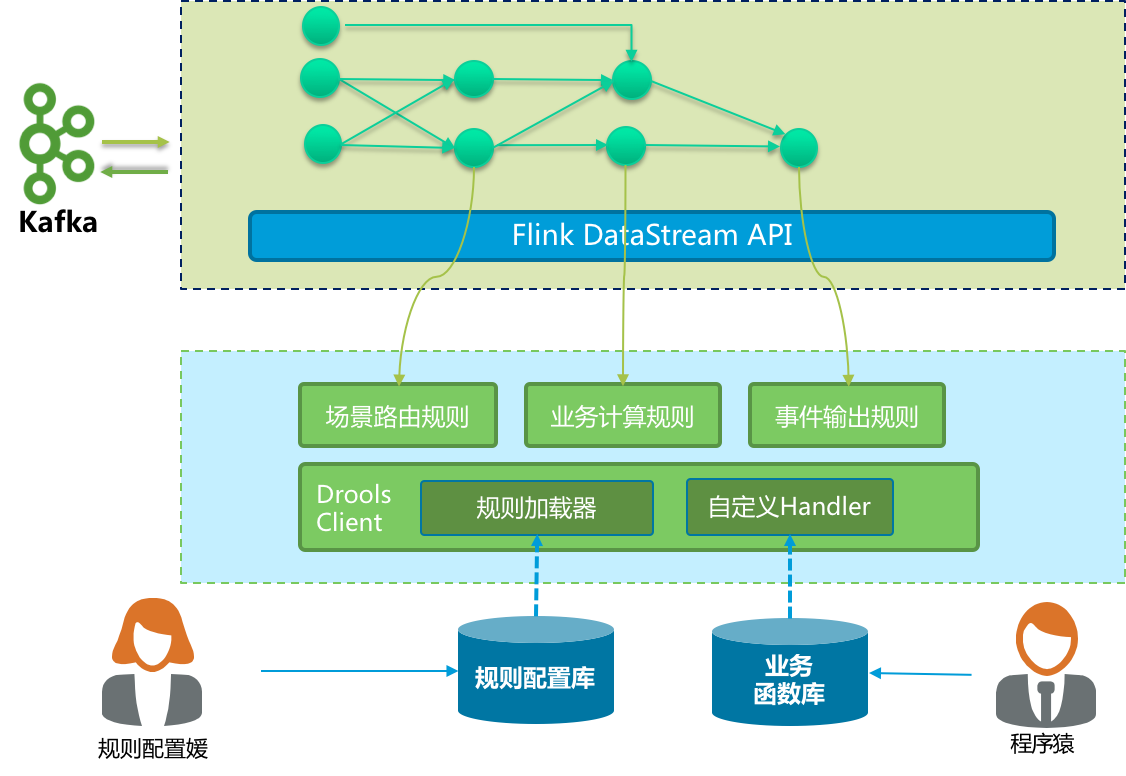
通过这一设计,为我们带来以下收益:
- 从复杂的需求实现中解脱出来,同时避免了硬编码方式产生大量的重复代码;
- 基于规则引擎(Drools)将业务规则从Flink到operator实现中剥离,实现规则热部署;
- 由于规则引擎服务独立部署,使得针对规则计算的性能优化便于实施;
数据模型治理
示例系统只是我们实施数十个项目之一,而且随着业务的发展,还会有更多、更复杂的数据项目运行在数据平台之上。如何有效管理数据模型快速膨胀的复杂度,就摆在我们面前、必须解决的挑战。
为此,我们拓展了上文的数据平台Web Console ,通过采集数据源、中间存储、目标存储的Metadata,解析ETL SQL,再配合手工录入,初步形成了基本的元数据管理。
主要功能包括:
- 自动监控与获取
- 检索与管理
- 数据模型变更日志
- 数据血缘关系(开发中)
- 数据地图(开发中)
除了元数据管理,我们还对业务系统的数据质量进行“预”管理。
- 主数据管理系统(MDM),主数据包括客户、网络、行政区划、地址库、线路等。
- 数据处理全流程监控
- 交叉钩稽检查(开发中)
数据模型治理是需要长期投入的工作,但却是保障企业数据资产有效管理和不断升值的最重要工作。我们很庆幸在平台建设初期就意识到这一点,为后续发展奠定了良好基础。
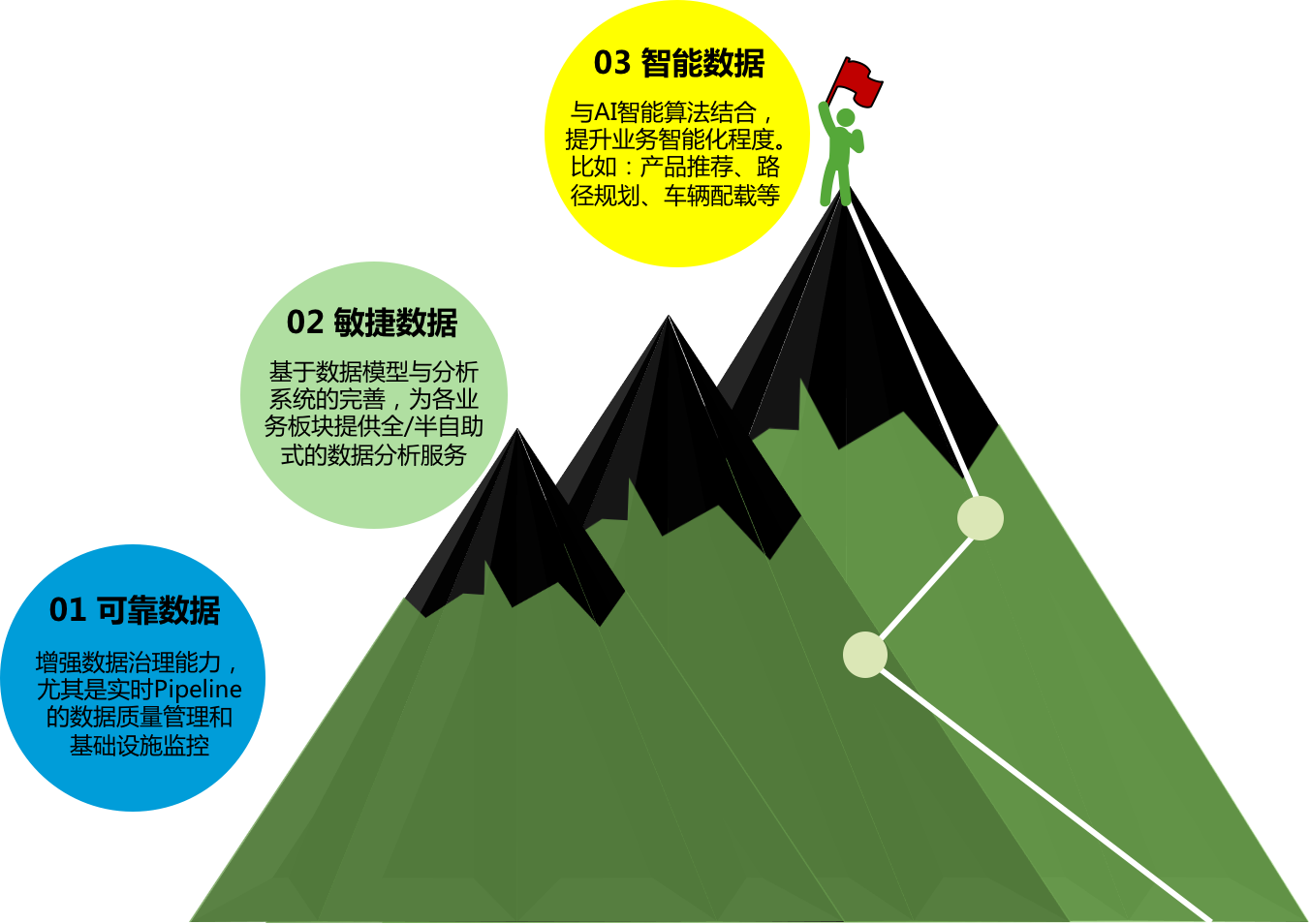
未来展望
以上,介绍了B端数据平台的特点和挑战,以及应对这些特殊挑战的设计方案。但由于产业互联网尚处在起步阶段,还有很长的路要走。因此,我们的数据平台也需要不断的进化和成长。
未来,我们计划从以下三个方向不断实践,希望能最大限度的释放大数据的能力,创造更多业务价值。
到这里,我今天的分享就差不多了。主要想将我们在toB业务中的实践心得分享给大家。让大家对toB数据平台有一个概要性的了解。由于篇幅关系,很多内容只能“点到为止”,欢迎大家访问我的个人博客深入沟通。产业互联网被大佬们认为互联网的下半场,相信从战略、战术、到踢球的规则、脚法都有很多不同,期待各位志同道合者深入交流。